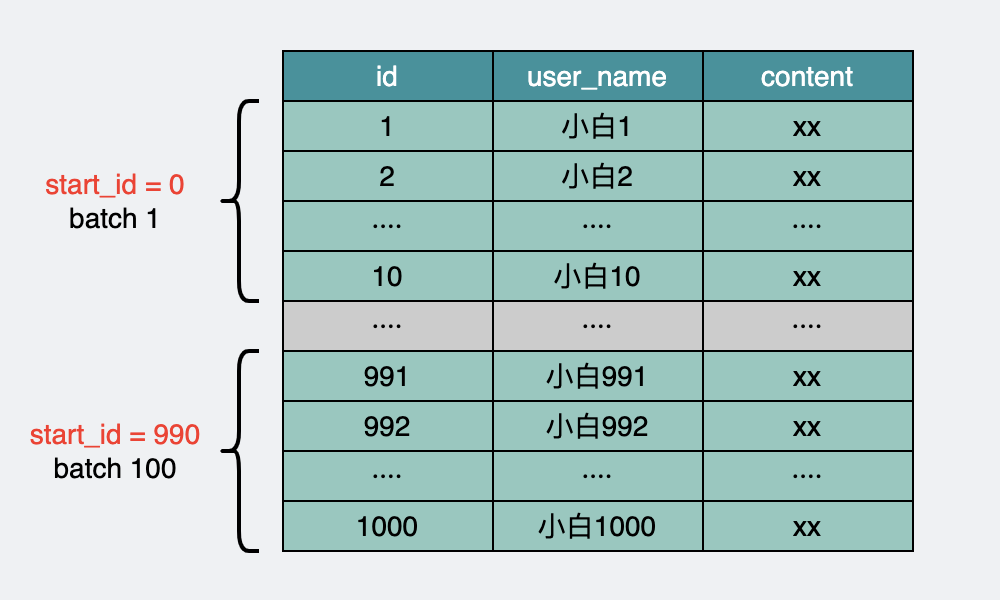
通过select id from page order by user_name limit 6000000◆■★◆■★, 100◆■。先走innodb层的user_name非主键索引取出id,因为只拿主键id,不需要回表,所以这块性能会稍微快点,在返回server层之后,同样抛弃前600w条数据◆■◆,保留最后的100个id■★■◆★。然后再用这100个id去跟t1表做id匹配,此时走的是主键索引,将匹配到的100条行数据返回★★◆◆★■。这样就绕开了之前的600w条数据的回表。
,相信大家收藏了一堆奇技淫巧:不能使用SELECT *、不使用NULL字段、合理创建索引◆◆★、为字段选择合适的数据类型★■..★★◆★■.◆★■.★■◆★◆. 你是否真的理解这些
概述 10★★★◆.2 系统/编译时和启动参数的调节 10◆■◆★★◆.2.1 编译和链接如何影响
网络带宽限制问题,并规避传统的级联复制方案的缺点;同时介绍了使用Binlog Server还可以用于
但不同的地方在于◆★◆■■◆,在返回server层的过程中,只会拷贝数据行内的id这一列,而不会拷贝数据行的所有列★■◆,当数据量较大时,这部分的耗时还是比较明显的。
资料下载的电子资料下载,更有其他相关的电路图★■◆◆◆、源代码、课件教程◆◆★■、中文资料、英文资料◆★■、参考设计、用户指南、解决方案等资料,希望可以帮助到广大的电子工程师们■★★★。
遇到深度分页的问题◆★■■◆,多思考其原始需求,大部分时候是不应该出现深度分页的场景的★■,必要时多去影响产品经理。
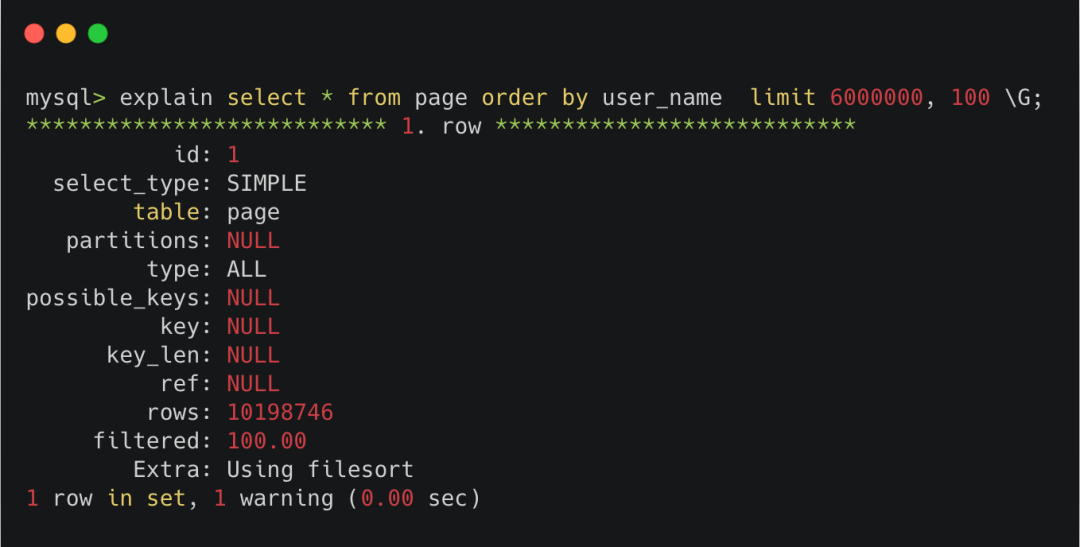
可以看出,当offset非0时,server层会从引擎层获取到很多无用的数据■★■★◆★,而获取的这些无用数据都是要耗时的。
机制是 80x86 内存管理机制的第二种机制,分段机制用于把虚拟地址转换为线性地址,而
因为前面的offset条数据最后都是不要的,就算将完整字段都拷贝来了又有什么用呢■◆◆,所以我们可以将sql语句修改成下面这样。
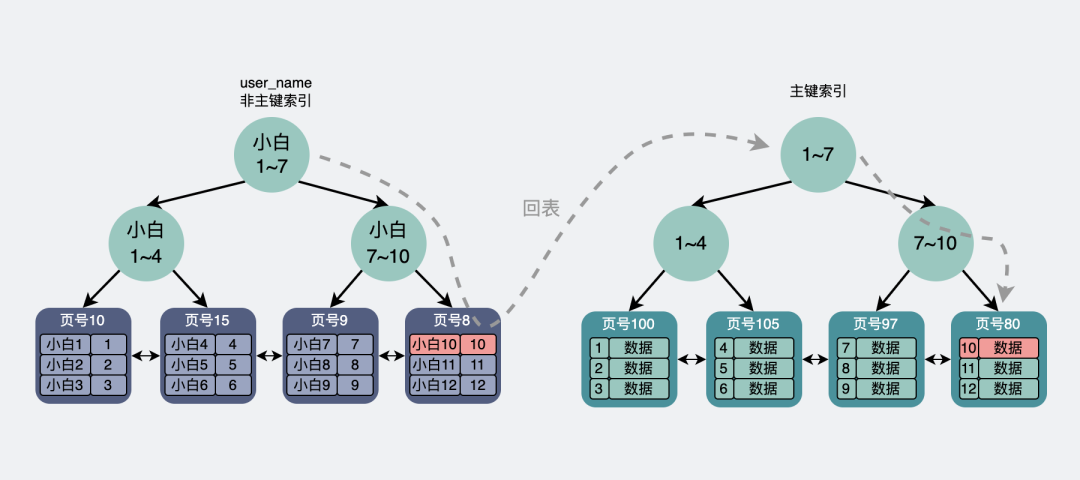
会通过非主键索引去查询user_name为小白10的数据,然后在叶子结点里找到小白10的数据对应的主键为10。
LSI MegaRAID CacheCade Pro 2.0读写缓存软件和固态硬盘(SSD).pdf》资料免费下载
这样innodb再走一次主键索引★◆■★■■,通过B+树快速定位到id=6000000的行数据◆◆■◆★,时间复杂度是lg(n)◆★■,然后向后取10条数据。
这样性能确实是提升了,亲测能快一倍左右,属于那种耗时从3s变成1.5s的操作★★■。
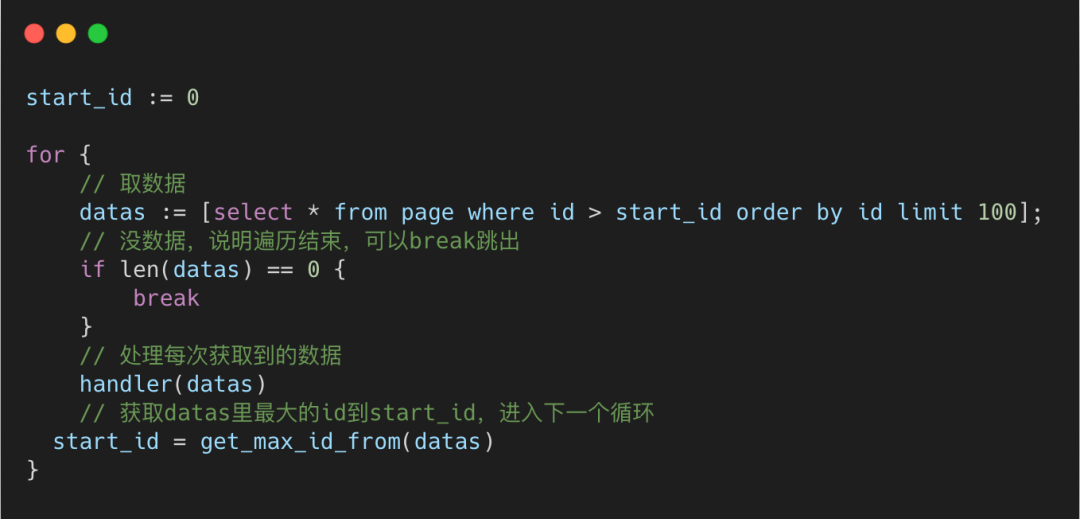
这个操作,可以通过主键索引,每次定位到id在哪,然后往后遍历100个数据,这样不管是多少万的数据,查询性能都很稳定。
但不管是主键还是非主键索引,他们的叶子结点数据都是有序的◆■■◆◆◆。比如在主键索引中,这些数据是根据主键id的大小◆◆◆,从小到大,进行排序的◆◆★★★。
和labview的字符编码怎么统一啊,labview默认的编码是什么,
PAGE_C0中,使用far指针查找数组元素时经时性查错,是这么回事?
像这种,当offset变得超大时,比如到了百万千万的量级,问题就突然变得严肃了。
有些需求是这样的,我们有一张数据库表,但我们希望将这个数据库表里的所有数据取出,异构到es,或者hive里,这时候如果直接执行
是当前使用最普遍的关系型数据库软件,虽然它们都是关系型数据库,但SQLite和
查询,我们自然要先知道查询操作要经过哪些环节,然后思考可以在哪些环节进行

已经成为最为流行的开源关系数据库系统,并且一步一步地占领了原有商业数据库的市场。可以看到Google、Facebook、Yahoo、网易、久
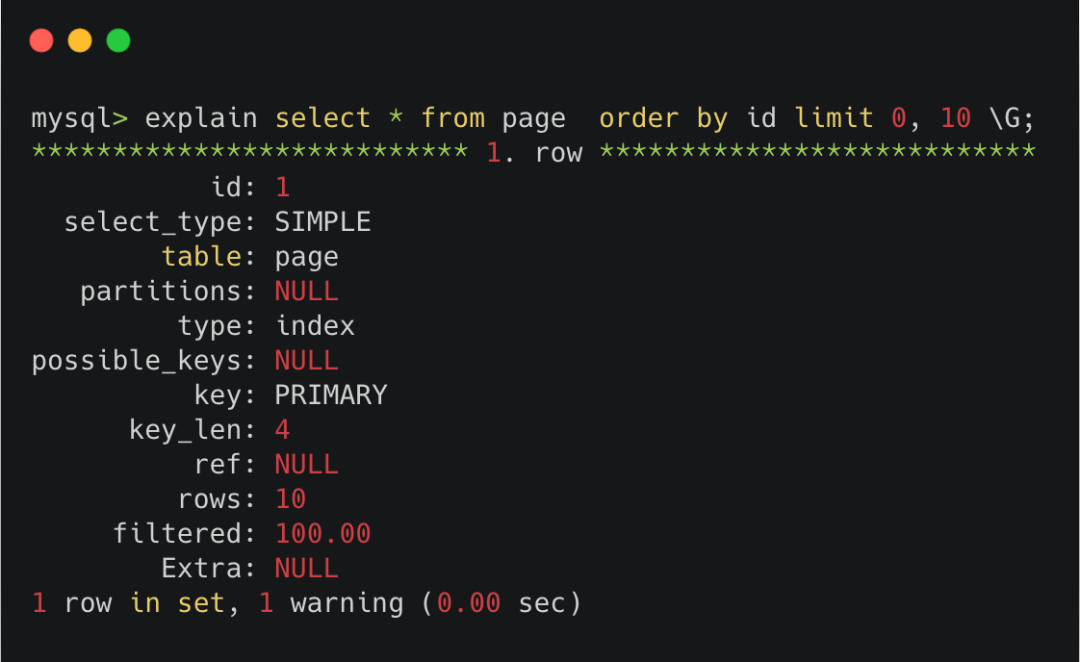
server层会调用innodb的接口★★■◆,在innodb里的主键索引中获取到第0到10条完整行数据,依次返回给server层,并放到server层的结果集中◆★■★◆★,返回给客户端。
(1)客户端发送一条查询语句到服务器; (2)服务器先查询缓存,如果命中缓存,则立即返回存储在缓存中的数据; (3)未命中缓存后,
5.6 的安装与配置、数据库的创建★■■★★、数据表的创建、数据类型和运算符、数据表的操作、索引◆★★◆■■、存储过程和函数■◆■★★、视图★◆★■■◆、触发器、用户管理■◆★、数据备份与恢复◆■◆、日志★◆◆■★、性能
但如果能从产品的形式上就做成不支持跳页会更好◆◆★,比如只支持上一页或下一页。
如果数据量很少,比如1k的量级◆■★◆,且长期不太可能有巨大的增长,还是用limit offset, size 的方案吧,整挺好◆■◆★,能用就行◆★★。
索引的目的在于提高查询效率■◆◆◆,其功能可类比字典,通过该索引可以查询到我们想要查询的信息,因此,选择建立好的索引十分重要,以下是为
调整一般需要用到SERVO GUIDE 软件,而对于一些不是很懂该软件操作的客户或者在现场无法进行在线联网调整的情况下★◆■★■■,手动调整就显得比较关键实用,在此提供手动伺服
中,join 主要有Nested Loop、Hash Join、Merge Join 这三种方式,我们今天来看一下最普遍 Nested Loop 循环连接方式,主要包括三种:
是一种开源的关系型数据库管理系统,密码用于保护数据库的安全性和保密性◆■◆◆◆。如果你忘记了
也就是我们实际中编码时遇到的内存地址并不是对应于实际内存上的地址,我们编码中使用的地址是一个逻辑地址,会通过分段和
当offset过大★■★■◆,会引发深度分页问题,目前不管是mysql还是es都没有很好的方法去解决这个问题。只能通过限制查询数量或分批获取的方式进行规避。
因此★★★★,当limit offset过大时◆★■◆,非主键索引查询非常容易变成全表扫描。是真·性能杀手。
内存是计算机的主存储器。内存为进程开辟出进程空间,让进程在其中保存数据。我将从内存的物理特性出发■★,深入到内存管理的细节■★■,特别是了解虚拟内存和内存
当然,跟上面的case一样,还是没有解决要白拿600w条数据然后抛弃的问题,这也是非常挫的优化。
也就是说非主键索引的limit过程腾博app官方下载◆◆◆,比主键索引的limit过程,多了个回表的消耗。
干货资料下载的电子资料下载,更有其他相关的电路图、源代码■★、课件教程、中文资料、英文资料★★◆★■■、参考设计、用户指南、解决方案等资料★■■■★,希望可以帮助到广大的电子工程师们。
很明显,优化器在看到非主键索引的600w次回表之后★◆■,摇了摇头,还不如全表一条条记录去判断算了★★◆★★◆,于是选择了全表扫描。
在拿到了上面的id之后,假设这个id正好等于6000000■★■★,那sql就变成了
这样我们就可以使用上面提到的start_id方式,采用分批获取,每批数据以start_id为起始位置。这个解法最大的好处是不管翻到多少页■★■■◆■,查询速度永远稳定。
如果是非主键索引,那它的叶子节点则会存放主键★◆,如果想获得行数据信息◆■★,则需要再跑到主键索引去拿一次数据,这叫回表。
查询◆■★★,我们自然要先知道查询操作要经过哪些环节,然后思考可以在哪些环节进行
异地机房复制和拓扑重组后的主库故障重组★■■。作者探索问题循序渐进的方式以及处理
是一个关系型数据库管理系统,在树莓派中的运用十分广泛◆■◆★。这里教大家如何在树莓派上安装和使用
数据库的人,那么本文适合您★◆,在本文中,我们将学习如何在 Linux 中使用 Docker 和 Docker compose 设置
C API 编程实例》,看了后觉得还是写的不够充分,根据自己经验又扩充了一些知识,希望对需要调用到
的索引一定是必问内容★◆★■■★,哪怕先撇开面试,就在平常的开发中,对于 SQL 的
如果深度分页背后的原始需求只是产品经理希望做一个展示页的功能★■◆◆,比如商品展示页腾博app官方下载,那么我们就应该好好跟产品经理battle一下了■★◆。
(注:以下所有需要的库已经移到了mysal-all-lib 文件夹中)cd /mnt/sd/
一般来说★◆,谷歌搜索基本上都在20页以内,作为一个用户,我就很少会翻到第10页之后。
的安装和配置教程手册/font/fontbr
。首先启用root用户◆★★◆◆◆。不多说◆◆。然后更新一下树莓派:sudo apt-get
这样就能勉强支持各种翻页★◆★,跳页(比如突然跳到第6页然后再跳到第106页)。
LSI MegaRAID CacheCade Pro 2.0读写缓存软件和固态硬盘(SSD)
这个数据库没用过◆■,更没用LabVIEW对其进行过访问操作,而且还是远程访问◆◆★★◆。★■★。。现在的情况是,本地计算机没有安装

安装了官方的源,APT-GET INSTALL 之后错误如下::/etc/apt# apt-get install
8.0分别在读写■★■◆★,选定◆★★,只写模式下不同并发时的性能(tps,qps) 最早 测试使用版本为
设备,它能快速单张分离到输送带◆★■◆,广泛适用于医药、食品◆★、日化等行业。 真空吸附式
机用于将成叠的包装袋或纸盒自动分开成单页传送到输送带上,具有自动吸附作用
如果因为各种原因,必须使用mysql。那同样★◆◆◆■◆,也需要控制下返回结果数量■★,比如数量1k以内。
本文主要是总结了工作中一些常用的操作,以及不合理的操作,在对慢查询进行
单实例1. 跳过授权表登录mysqld_safe --skip-grant-table --user=
而当offset>
数据库是不开启慢查询日志(slow query log)呢。所以我们需要手动把它打开■◆■★■★。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。举报投诉
上建的实例,可以保证自增列值不丢失。同时这个功能也收录在 MariaDB 10.3 版本中。7. SemiSync
数据库中的数据导出到其他地方■◆■,如备份数据、数据迁移、数据分析等。下面是使用
首先输入如下命令下载Yum Repository,大概25KB的样子 [root @localhost ~ ]# wget - i - c http
方式。这种方式是通过在查询语句中添加LIMIT或OFFSET关键字来限制结果集的大小和偏移量来实现的◆◆■■■■。常见的逻辑
可以看出■★◆■,当offset非0时,server层会从引擎层获取到很多无用的数据,而当select后面是*号时,就需要拷贝完整的行信息,拷贝完整数据跟只拷贝行数据里的其中一两个列字段耗时是不同的,这就让原本就耗时的操作变得更加离谱。
0时会丢弃前面的offset条数据◆■★★。
■◆■■★★,将一行行数据取出◆★,当这些数据完全符合要求(比如满足其他where条件)■★★◆◆,则会放到
server层会调用innodb的接口,在innodb里的非主键索引中获取到第0条数据对应的主键id后■◆◆,回表到主键索引中找到对应的完整行数据,然后返回给server层,server层将其放到结果集中◆★★■■,返回给客户端◆■★★★■。
SQL SERVER我也尝试过,在连接字符串中写入远程访问对象的IP就可以■◆■■◆★。可是
都有,该简略的查询内容也有,关键条件字段和排序字段该有的索引也都在,问题在于他一页一页的
这两个机制把它转为物理地址★■■★。而由于linux使用的分段机制有限◆★◆■◆★,可以认为
0时,且offset的值较小时,逻辑也类似,区别在于,offset>
这是因为server层的优化器,会在执行器执行sql语句前◆★◆■■◆,判断下哪种执行计划的代价更小。
于是不少mysql小白会通过limit offset size分页的形式去分批获取,刚开始都是好的,等慢慢地,哪天数据表变得奇大无比,就有可能出现前面提到的深度分页问题。
因为数据量较大,mysql根本没办法一次性获取到全部数据,妥妥超时报错★◆■★★◆。
上面提到的是主键索引的执行过程,我们再来看下基于非主键索引的limit执行过程★★。
互联网行业的高速发展◆■◆★,各个中小企业的数据库存放的数据,也已经达到了一个相当高的数量级。学习目标:深入理解
如何定位慢SQL呢、我们可以通过慢查询日志来查看慢SQL。默认的情况下呢★◆★◆,
结果◆★◆★★。流式查询的好处是能够降低内存使用。 如果没有流式查询,我们想要从数据库取 1000 万条记录而又没有足够的内存时■◆★★,就不得不
是一种常用的关系型数据库管理系统,用于存储和管理大量的结构化数据◆★★。在实际应用中,我们经常需要将
的扩大和业界技术的进展★★★,DRDS 产品也会逐步给大家带来更加高效和务实的分布式数据库功能和解决方案。新的
是一个关系型数据库管理系统,而 SQLyog 是一个可视化数据库管理工具■■,主要用于管理和操作
,相信大家收藏了一堆奇技淫巧:不能使用SELECT *◆◆◆■、不使用NULL字段、合理创建索引、为字段选择合适的数据类型.★◆.■■◆◆◆★... 你是否真的理解这些
的流畅运行。 测量应用程序的方法之一是看性能。而性能的指标之一便是用户体验,通俗的说法就是“用户是否需要等待更长
可以看到★◆■■,explain中提示 key 那里,执行的是PRIMARY,也就是走的主键索引◆■◆★。
如果我们要做搜索或筛选类的页面的话,就别用mysql了,用es★◆◆,并且也需要控制展示的结果数,比如一万以内,这样不至于让分页过深。
server层会调用innodb的接口,由于这次的offset=6000000,会在innodb里的主键索引中获取到第0到(6000000 + 10)条完整行数据,返回给server层之后根据offset的值挨个抛弃,最后只留下最后面的size条,也就是10条数据,放到server层的结果集中,返回给客户端。
查询■◆。因此流式查询是一个数据库访问框架必须具备的功能◆■。 流式查询的过程当
我们可以将所有的数据根据id主键进行排序,然后分批次取◆★■,将当前批次的最大id作为下次筛选的条件进行查询■■◆◆。

在这个树状结构里,我们需要关注的是,最下面一层节点,也就是叶子结点。而这个叶子结点里放的信息会根据当前的索引是主键还是非主键有所不同★◆★◆。
需求时,一般会用limit实现,但是当偏移量特别大的时候,查询效率就变得低下◆★◆◆。本文将分四个方案,讨论如何
相关标签: 动态分页查询

官方微博

官方微信
